Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
论文链接:https://arxiv.org/pdf/2506.05176
代码链接:https://github.com/QwenLM/Qwen3-Embedding
摘要
本文介绍了 Qwen3 Embedding 系列,该系列基于 Qwen3 基础模型构建,在文本嵌入和重排序能力方面较其前身 GTE-Qwen 系列有了显著提升。Qwen3 充分利用了 Qwen3 LLM 在多语言文本理解和生成方面的强大能力,我们创新的多阶段训练流程将大规模无监督预训练与高质量数据集上的有监督微调相结合。有效的模型融合策略进一步确保了 Qwen3 Embedding 系列的鲁棒性和适应性。在训练过程中,Qwen3 LLM 不仅作为骨干模型,还在跨多个领域和语言合成高质量、丰富且多样化的训练数据方面发挥着关键作用,从而增强了训练流程。Qwen3 Embedding 系列为嵌入和重排序任务提供了多种模型规模(0.6B、4B 和 8B),以满足不同的部署场景,用户可以根据需要优化效率或效果。实证评估表明,Qwen3 Embedding 系列在各种基准测试中均取得了最先进的结果。尤其值得一提的是,它在用于文本嵌入的多语言评估基准测试 MTEB 以及各种检索任务(包括代码检索、跨语言检索和多语言检索)中均表现出色。为了便于复现并促进社区驱动的研究和开发,Qwen3 嵌入模型已根据 Apache 2.0 许可证公开提供。
1.介绍
文本嵌入和重排序是众多自然语言处理和信息检索应用的基础组成部分,包括网络搜索、问答系统、推荐系统等等。高质量的文本嵌入使模型能够捕捉文本之间的语义关系,而有效的重排序机制则确保优先呈现最相关的结果。近年来,随着大型语言模型(例如 Qwen3、GPT-4o)的进步,检索增强生成 (RAG) 和 Agent 系统等新兴应用范式的出现,对文本嵌入和重排序提出了新的要求和挑战,无论是在模型训练范式还是应用场景方面。尽管取得了显著进展,但训练出在可扩展性、上下文理解以及与特定下游任务的契合度方面表现良好的嵌入和重排序模型仍然具有挑战性。
大语言模型(LLM)的出现显著推动了文本嵌入和重排序模型的发展。在 LLM 出现之前,主流方法是使用仅包含编码器的预训练语言模型(例如BERT)作为基础模型进行训练。LLM 固有的更丰富的世界知识、文本理解和推理能力,使得基于这些架构训练的模型性能得到了进一步提升。此外,大量研究致力于将 LLM 集成到训练数据合成和高质量数据过滤等流程中。LLM 的基本特性也启发了新的训练范式的出现。例如,在嵌入模型训练过程中,融入不同维度(例如指令类型、领域和语言)的差异化任务,可以提高下游任务的性能。类似地,在重排序模型训练方面,基于用户提示的零样本方法和结合有监督式微调的方法都取得了进展。
本文介绍了基于 Qwen3 基础模型构建的 Qwen3 Embedding 系列模型。由于 Qwen3 同时发布了基础模型和指令模型,我们利用这些模型强大的多语言文本理解和生成能力,充分发挥其在训练嵌入和重排序模型方面的潜力。为了训练嵌入模型,我们实现了一个多阶段训练流程,包括大规模无监督预训练和在高质量数据集上的有监督微调。我们还采用了模型合并以及多个模型 checkpoint 来增强模型的鲁棒性和泛化能力。Qwen3 指令模型能够高效地合成一个庞大、高质量、多语言、多任务的文本相关性数据集。该合成数据用于初始的无监督训练阶段,而从中选取一个高质量、小规模的数据子集用于第二阶段的有监督训练。对于重排序模型,我们采用了类似的两阶段训练方案,包括高质量的有监督式微调和模型融合阶段。基于不同规模的 Qwen3 骨干模型(包括0.6B、4B和8B),我们最终训练了三个文本嵌入模型和三个文本重排序模型。为了便于它们在下游任务中的应用,Qwen3 Embedding 系列支持多种实用功能,例如嵌入模型的灵活维度表示以及嵌入模型和重排序模型的可自定义指令。
我们使用涵盖多个任务和领域的综合基准测试集对 Qwen3 Embedding 系列模型进行了评估。实验结果表明,我们的嵌入和重排序模型达到了最先进的性能,在多个检索任务中与领先的专有模型展开了激烈的竞争。例如,旗舰模型 Qwen3-8B-Embedding 在 MTEB 多语言基准测试上取得了 70.58 分,在 MTEB 代码基准测试上取得了 80.68 分,超越了之前最先进的专有嵌入模型 Gemini-Embedding。此外,我们的重排序模型在一系列检索任务中也取得了具有竞争力的结果。 Qwen3-Reranker-0.6B 模型在众多检索任务中超越了以往表现最佳的模型,而规模更大的 Qwen3-Reranker-8B 模型则展现出更为卓越的性能,在多个任务中排名结果比 0.6B 模型提高了 3.0 分。此外,我们还进行了一项构造性消融实验,以阐明 Qwen3 Embedding 系列模型性能优异的关键因素,从而深入了解其有效性。
在接下来的章节中,我们将描述模型架构的设计,详细介绍训练过程,展示 Qwen3 嵌入系列嵌入模型和重排序模型的实验结果,并通过总结关键发现和概述未来研究的潜在方向来结束本技术报告。
2.Model Architecture
嵌入和重排序模型的核心思想是以任务感知的方式评估相关性。给定一个 qeury 和一个文档 ,嵌入和重排序模型基于指令 定义的相似性准则来评估它们的相关性。为了使模型能够进行任务感知的相关性估计,训练数据通常组织成 ,其中 表示 query 的正例(相关)文档,而 表示负例(不相关)文档。在不同的文本对上训练模型可以扩展其在各种下游任务中的适用性,包括检索、语义文本相似性、分类和聚类。
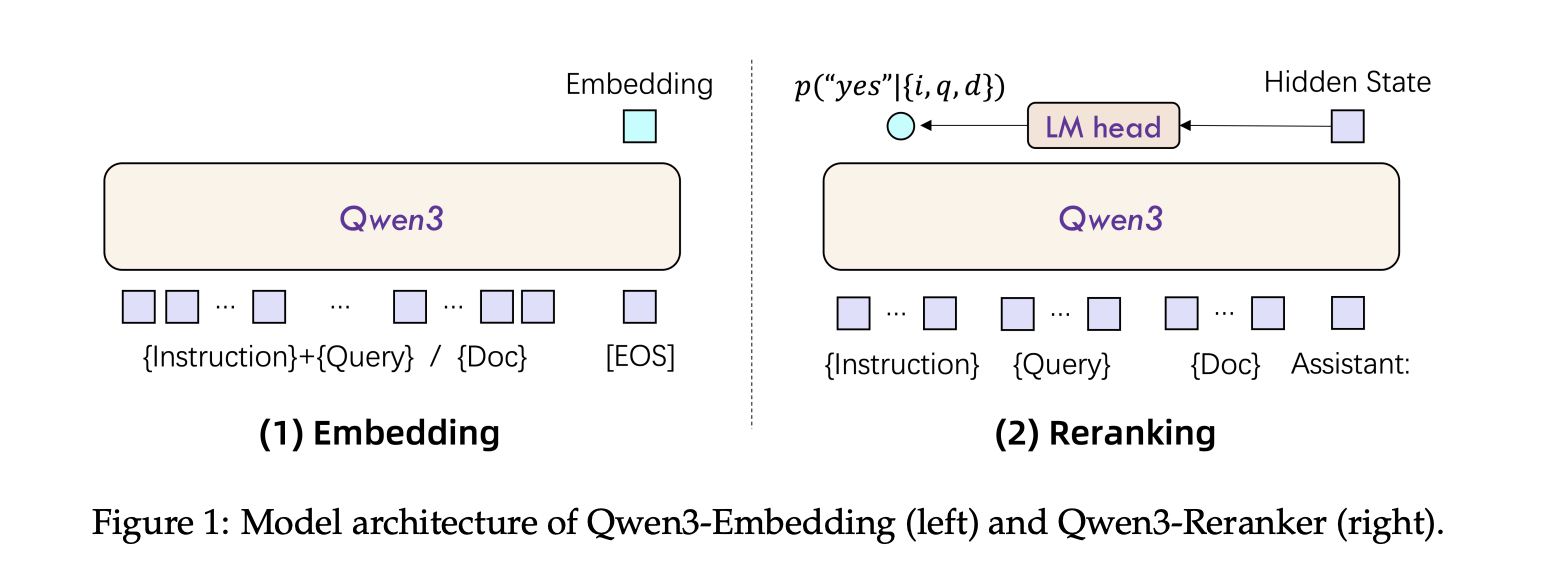
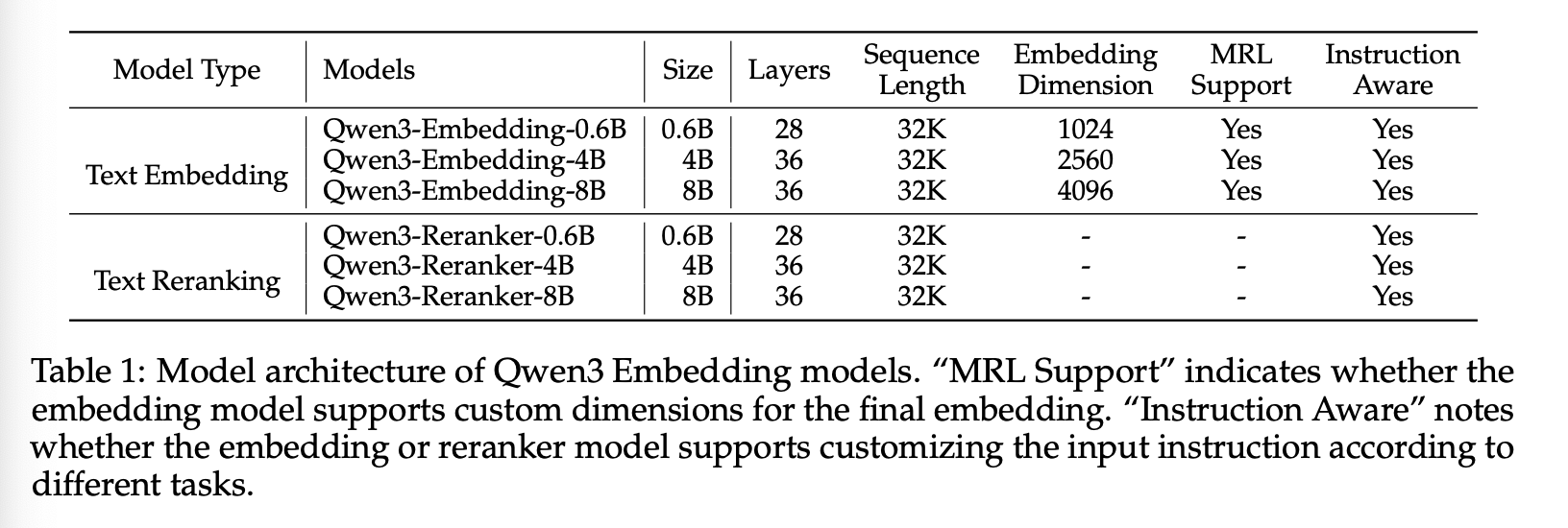
Architecture。Qwen3 嵌入和重排序模型基于 Qwen3 基础模型的密集版本构建,并提供三种规模:0.6B、4B 和 8B 参数。我们使用 Qwen3 基础模型初始化这些模型,以充分利用其在文本建模和指令跟踪方面的能力。表 1 详细列出了每种模型配置的模型层数、隐藏层大小和上下文长度。
Embedding Models。对于文本嵌入,我们使用带有因果注意力机制的层级模型(LLM),并在输入序列末尾添加一个 [EOS] token。最终的嵌入向量源自与该 [EOS] 标记对应的最后一层的隐藏状态。
为了确保嵌入在下游任务中遵循指令,我们将指令和 query 连接成一个单一的输入上下文,同时在用 LLM 处理之前保持文档不变。query 的输入格式如下:
Reranking Models。为了更准确地评估文本相似度,我们采用 LLM 模型在单个上下文中进行逐点重排序。与嵌入模型类似,为了实现指令遵循功能,我们在输入上下文中包含了指令。我们使用 LLM 聊天模板,并将相似度评估任务建模为二元分类问题。LLM 的输入遵循以下模板:
为了根据给定的输入计算相关性得分,我们评估下一个 token 为“yes”或“no”的可能性。这可以用数学公式表示如下:
3.Models Training
在本节中,我们将介绍所采用的多阶段训练流程,并介绍该训练方案的关键要素,包括训练目标、训练数据合成和高质量训练数据的筛选。
3.1 Training Objective
在介绍我们的训练流程之前,我们首先概述训练过程中用于嵌入模型和重排序模型的优化损失函数。
3.1.1 Embedding Model
对于嵌入模型,我们采用基于 InfoNCE 框架的改进对比损失。给定一批 个训练样例,损失定义如下:
其中 为相似度函数(我们使用余弦相似度), 为温度参数, 为归一化因子,用于聚合正样本对与各种负样本对的相似度得分:
其中,这些项表示与以下各项的相似度:(1)正例文档 ,(2) 个难负例文档 ,(3)batch 内其他查询 ,(4)batch 内其他文档 与正例文档 的比较,(5)批次内其他文档 与查询 的比较。掩码因子 旨在减轻假阴性的影响,其定义如下:
其中 是 或 的对应分数。
3.1.2 Reranking Model
对于重排序模型,我们优化有监督微调(SFT)损失,其定义如下:
其中 表示 LLM 分配的概率。标签 对于正例文档为“yes”,对于负例文档为“no”。该损失函数鼓励模型为正确标签分配更高的概率,从而提高排序性能。
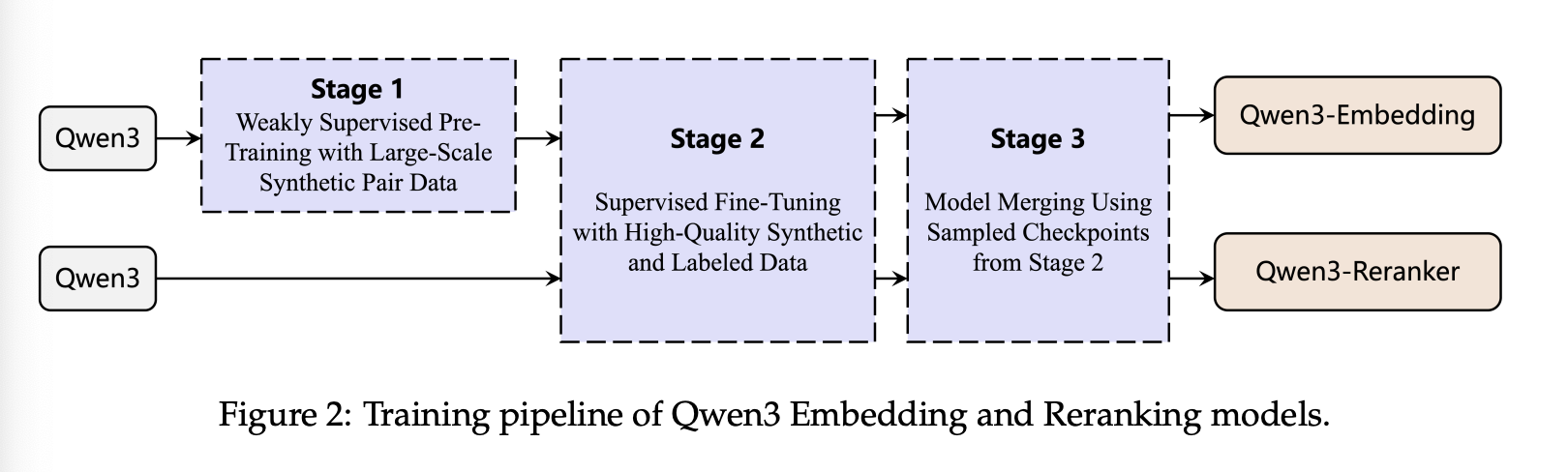
3.2 Multi-stage Training
多阶段训练方法是训练文本嵌入模型的常用方法。该策略通常首先使用包含噪声的大规模半监督数据集进行初始训练,然后使用规模较小、质量较高的监督数据集进行微调。这种两步过程可以提升嵌入模型的性能和泛化能力。大规模弱监督训练数据对模型的泛化能力贡献显著,而后续阶段使用高质量数据进行微调则可以进一步提升模型性能。嵌入模型的两个训练阶段均采用公式 1 中定义的优化目标,而重排序模型的训练则采用公式 2 中定义的损失函数作为优化目标。
Qwen3 Embedding 系列在现有多阶段训练框架的基础上,引入了以下关键创新:
- 大规模合成数据驱动的弱监督训练:与以往的研究(例如 GTE、E5、BGE 模型)不同,这些研究主要从问答论坛或学术论文等开源社区收集弱监督训练数据,而我们提出利用基础模型的文本理解和生成能力直接合成配对数据。这种方法允许在合成提示中任意定义所需配对数据的各个维度,例如任务、语言、长度和难度。与从开放领域来源收集数据相比,基础模型驱动的数据合成提供了更高的可控性,能够精确管理生成数据的质量和多样性,尤其是在资源匮乏的场景和语言环境下。
- 高质量合成数据在有监督微调中的应用:由于 Qwen3 基础模型的卓越性能,其合成数据质量极高。因此,在有监督训练的第二阶段,选择性地融入这些高质量合成数据,能够进一步提升模型的整体性能和泛化能力。
- 模型合并:受先前工作的启发,在完成有监督微调后,我们应用了一种基于球面线性插值(Slerp)的模型合并技术。该技术涉及合并微调过程中保存的多个模型检查点。此步骤旨在提升模型在各种数据分布上的鲁棒性和泛化性能。
值得注意的是,重排序模型的训练过程不包括第一阶段的弱监督训练阶段。